I’ve been a part of the Acervos Digitais (Digital Collections) research group at University of São Paulo since the beginning of 2024.
This is a research group funded by a FAPESP digital humanities grant and coordinated by Giselle Beiguelman, that aims to explore new distributed and open-source archive models for art, architecture and design collections.
My contributions have been in the development of prototypes for experimenting with Artificial Intelligence and Machine Learning techniques that allow for different ways of creating, augmenting and updating existing digital archives of public interest.
Meta-Acervos
The most recent project developed within this context involved creating a prototype to facilitate search and navigation of digital images of art works from Brazilian museum collections.
This involved scraping images and metadata from public accessible sources like wikidata, the Brasiliana platform, and sometimes directly from museums, like the MAC USP collection.
The metadata obtained from these sources, with information about the artworks’s author, title, medium and date of creation, was augmented with data generated from machine learning processes and AI models.

Some of the processing and data created included:
- K-means clustering algorithm to extract a set of representative colors from each work.
- Gemma 3 generative model to extract concise keyword and detailed descriptions of the images.
- Contrastive text-image models like CLIP and SigLIP to extract high-dimensional embeddings for each image and their keywords.
- Open-vocabulary model OWLv2 to detect and tag objects related to humans and nature present in the artworks.
- t-SNE and K-means clustering to separate images into a variable number of groups based on their visual features.
- Nearest Neighbors Classification to fill-in missing dates based on clustering and embedding information.
- Cosine similarity on embeddings to enable different kinds of dynamic searches.
The data created is available on GitHub and Huggingface
This augmented dataset not only allows for new ways of searching and organizing the collections, but also enables new ways of visualizing their content. One possibility is to place cropped objects on a blank canvas, sized and positioned relative to their original location in the complete artwork.
The images below show: (1) all the hands in religious paintings from all of the collections, and their relative locations, (2) all the hands and faces extracted from artworks in the National Historical Museum collection, and (3) all of the palm trees extracted from paintings created between the years 1800 and 1922:



A prototype to navigate these collections and create visualizations is available here.
A longer article about this project is forthcoming.
Arquigrafia
An earlier project developed within the Acervos Digitais research group was a collaboration with another research group that maintains an open database of crowd-contributed pictures of architecturally significant places and structures throughout Brazil.
The Arquigrafia project has more than 15,000 entries/images published on their website, with varying degrees of metadata about the buildings and structures pictured.
My goal for this prototype was to augment their archive with additional information that could help researchers find images by performing different kinds of searches.
The different kinds of searches enabled by the processing of the images were:
- By materials, objects and subjects: an open-vocabulary object detection model was used to detect structural terms, like: stairs, balcony, ramps, etc., as well as specific materials, like: cement, wood, glass, etc., and natural elements, like: grass, water, animals, etc.
- By keywords: open-source LLMs were also used to describe the images and extract nouns related to the structures photographed, objects present and overall composition of the images. This allows the images to be searched using a more general set of keywords.
- By colors: color quantization and clustering was done in order to extract a set of four representative hues for each image.
- By groups/clusters: the images were separated into eight groups based on embeddings extracted using a contrastive text-image model.
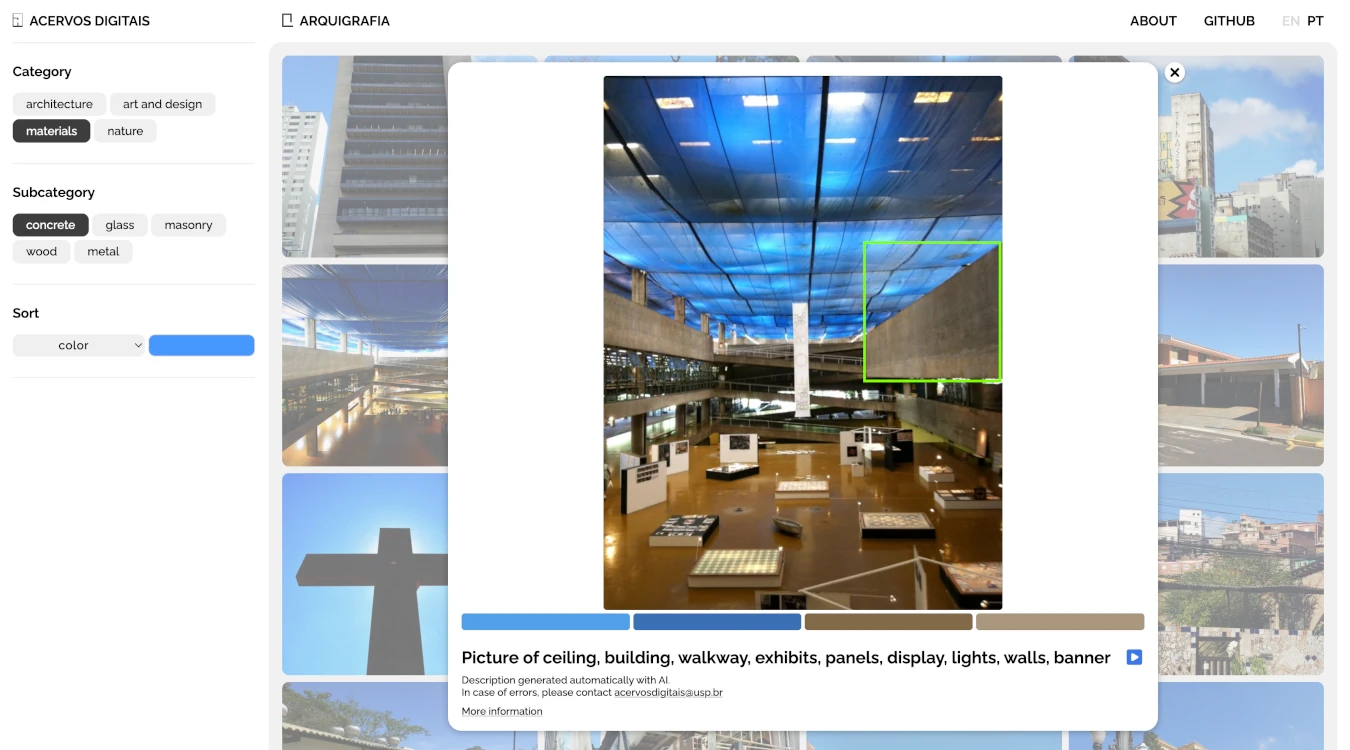
All of the generated metadata is available as a collection of JSON files, waiting to be integrated into the main Arquigrafia database/collection.
Our internal interface for testing and verifying the models and results can be accessed here.
08 January
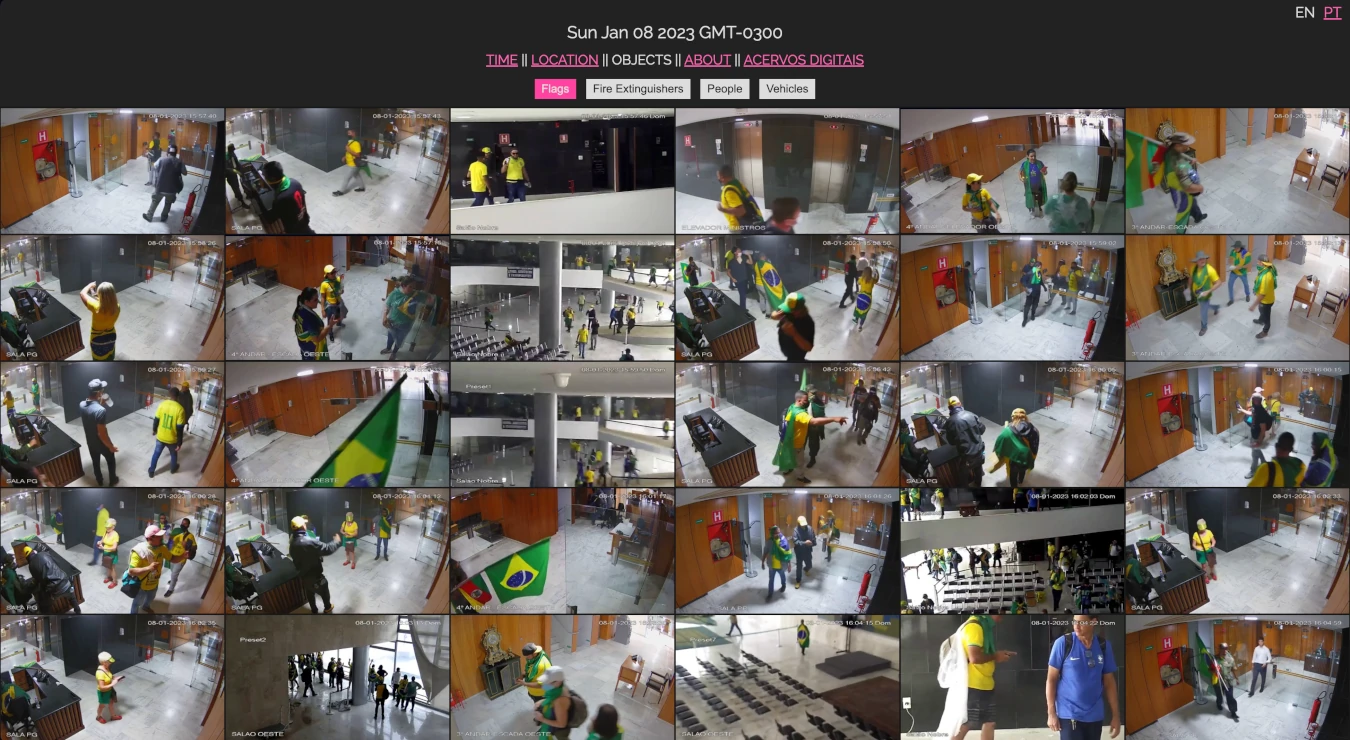
The first project developed in the Acervos group was an interface to help navigate the more than 500 hours of security camera footage recorded on 08 January, 2023, the day violent mobs invaded Brazil’s federal government buildings in Brasília.

A handful of preprocessing steps were taken in order to arrive at a final prototype that allows for journalists, researchers and artists to navigate the material by time of day, camera location and detected objects. This can be summarized as follows:
- Resizing/resampling: videos are all resized and resampled to have consistent resolution and frame rates.
- Time-stamping: Optical Character Recognition (OCR) models and computer vision techniques are used to extract the timestamp from video frames.
- Summarization: videos are summarized into keyframes and moments-of-interest using perceptual hashing keyframe analysis.
- Grouping/clustering: summarized frames are used to cluster unlabeled videos according to keyframes from labeled video files.
- Object Detection: an open-vocabulary model is used to detect a few different types of objects/concepts in the keyframes and moments-of-interest.
The resulting interface can be explored, here.
[1] Harvard Art Museums’ AI Explorer.
[2] Pietsch, Christopher (2014). VIKUS Viewer.
[3] Harvey, Adam (2021). VFRAME.
2024: Arquivo e Memória do Dia 8 de Janeiro de 2023, Arquivo Histórico Municipal - São Paulo, BR